


before: 2022
El año que murió Internet. Basura entra, basura sale. El techo de cristal de los LLMs. Humanos en el circuito.

El 30 de Noviembre de 2022 OpenAI lanzaba ChatGPT al mundo. En los libros de historia se estudiará como el principio del fin de Internet.
ChatGPT demostró al mundo que las IAs generativas de texto eran capaces de “escribir” mejor que muchos humanos. La consecuencia fue que Internet comenzó a llenarse de contenido. Contenido que en muchos casos se puede considerar basura.
Basura entra, basura sale
El término basura es relevante. En el contexto del desarrollo del software existe una expresión utilizada a menudo para representar que la calidad de las salidas de un sistema depende de la calidad de sus entradas: “Garbage In, Garbage Out”.
En otras palabras, si metes basura en un sistema, sólo puedes sacar basura. Por ejemplo, puedes pasarte días enteros haciendo los mejores análisis del planeta sobre un conjunto de datos, pero si los datos de inicio eran incorrectos, tus conclusiones van a ser erróneas.
Internet, cada día y gracias a los Large Language Models como ChatGPT, se está llenando de basura. A una velocidad absolutamente inusitada. Hasta el punto, de que ya hay personas añadiendo “before:2022” a sus búsquedas de Google para evitar obtener resultados contaminados por la IA.

El techo de cristal de los Large Language Models
Curiosamente, esta generación de basura también afecta a los LLMs, creando un techo de cristal a su propia capacidad de dar buenas respuestas.
Esto es así porque estos se entrenan con gran parte del contenido que se encuentra en Internet. Y, aplicando el mismo concepto de basura entra, basura sale, sus bases de entrenamiento están ya contaminadas. Cualquier contenido extraído de Internet a partir de 2022 corre serio riesgo de haber sido generado por una IA.
Los LLMs están generando así una barrera a su propio crecimiento. Barrera que deberán romper si quieren seguir mejorando sus modelos. O bien los OpenAI, Anthropic, Google y Meta encuentran la forma de distinguir claramente qué contenido es creado por un humano o ficticio, o bien tendrán que firmar acuerdos con proveedores de datos de prestigio que garanticen que hay humanos detrás de la generación del mismo.
Ya hemos empezado a ver movimientos en ese sentido. Reddit, por ejemplo, en su reciente salida a bolsa detallaba cómo ha firmado acuerdos para licenciar sus contenidos para los próximos tres años por más de 200 millones de dólares. En Europa, OpenAI anunciaba hace unos días acuerdos similares con El País y Le Monde.
¿Qué hacemos con la basura?
Mientras los grandes jugadores hacen acopio de fuentes de datos para sus modelos, esquivando su propia basura, ¿qué podemos hacer el resto de humanos con la que nos han dejado?
No estamos preparados para lidiar con ello. En Twitter, unos días atrás, un usuario comentaba lo que se había encontrado en el feed de su madre: una sucesión de posts generados por IAs que recibían los comentarios de otras personas mayores pensando que eran reales:

Pero los LLMs no se limitan a contaminar los posts. También se introducen en los comentarios, como cualquier usuario de Twitter puede experimentar a diario en su timeline.
Distinguir lo real de lo artificial va a ser una habilidad imprescindible. Lamentablemente, como especie, no tenemos un buen historial haciéndolo. Nuestros cerebros buscan siempre el camino más corto. Y si a eso le unimos algoritmos dispuestos a servirnos aquello que más nos retenga, independientemente de que sea cierto o no, el problema es mayúsculo.
Un humano en el circuito
Curiosamente, una posible solución a los problemas inherentes de los LLMs y la basura generada en Internet puede ser volver a introducir a los humanos en el circuito.
Un buen ejemplo son las Community Notes en Twitter, un sistema, mediante el cuál la comunidad puede unirse para dar contexto sobre un tweet concreto corrigiendo al autor.
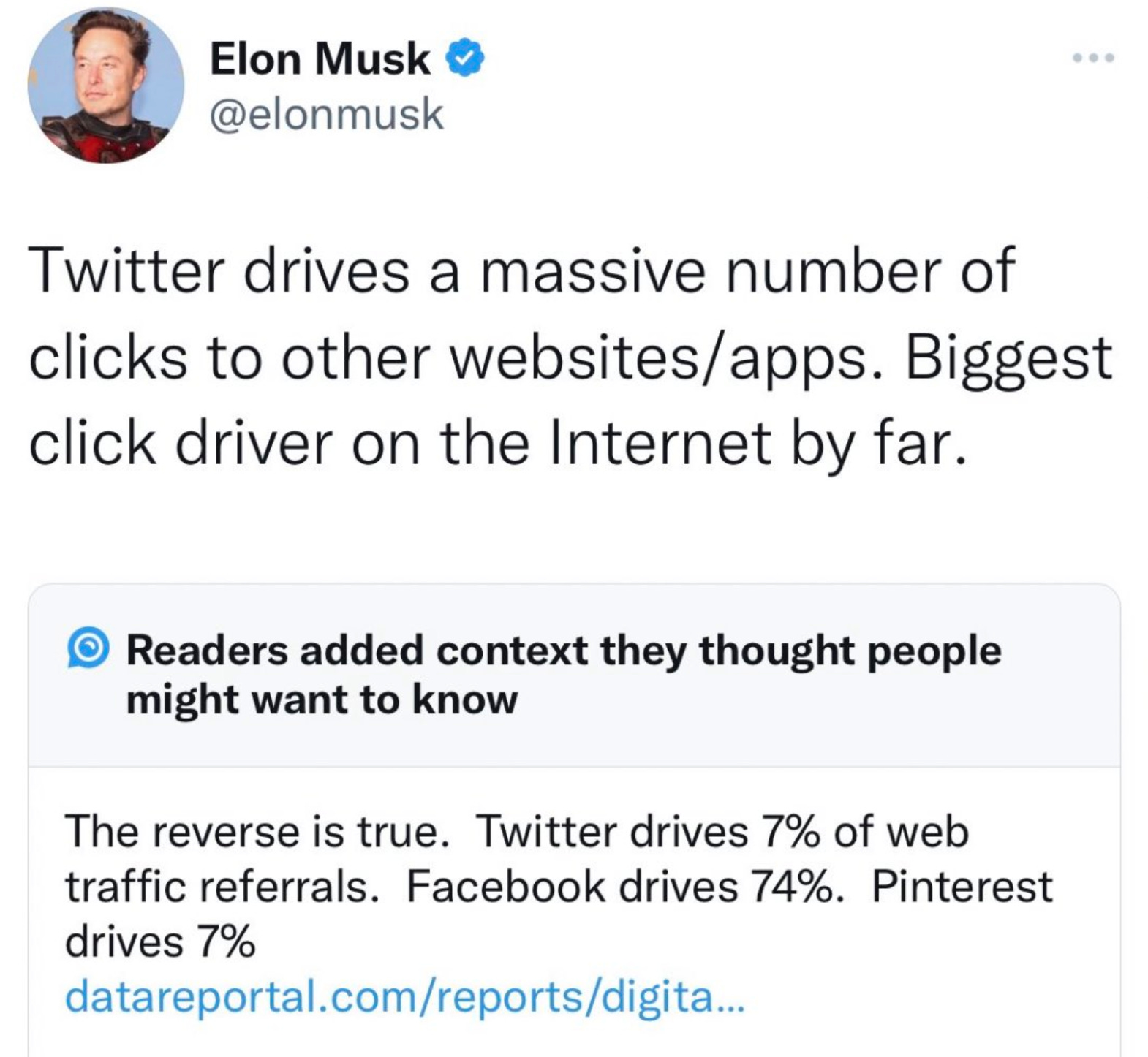
El problema de las Community Notes es que puedan terminar siendo utilizadas por otras subcomunidades para apoyar o censurar sus propios puntos de vista. Algo que cualquiera que haya gestionado una, sabe que termina ocurriendo antes o después.
Otra variante de volver a poner un humano en el circuito es utilizar a referentes de un sector para informarse. Personalmente, creo que la reciente explosión de listas de correo y podcasts tiene mucho que ver con tratar de filtrar nuestras fuentes de información. En un universo, dónde Google está cada vez más lleno de basura, la curación manual se vuelve vital.
El modelo no es nuevo, y, como las comunidades, puede ser explotado. Por ejemplo, los antiguos DJs de la radio en las épocas previas a Internet actúaban como curadores de la música, definiendo qué era popular y qué no. Sistema que aprovechó la industria musical para, a través de sobornos, proteger y evitar la competencia a sus artistas.
Quizás la solución sea una especie de firma criptográfica a modo de prueba de trabajo, permitiendo a los buscadores diferenciar claramente el contenido generado por un bot del creado por una persona de carne y hueso. La reputación de esa persona sería un factor de peso en los buscadores, que necesariamente deberían alterar sus algoritmos para reflejarlo. De nuevo, es un sistema que con el tiempo, sería explotado, pero, ¿cuál no?
La realidad es que mientras haya un incentivo para ganar dinero, siempre habrá alguien dispuesto a aprovecharlo. Y la tragedia de los comunes nos dice que irremediablemente terminaremos cargándonos el medio.
El medio en cuestión, es Internet.
Muy buen artículo. La IA (desde mi punto de vista) es interesante porque aumenta la mediocridad. Alguien que sabe poco, puede aprender o entender rápido las claves fundamentales de cualquier tema con la IA. Pero no deja de ser, nivel medio de conocimiento. "Saber de qué va".
La parte experta sigue estando reservada para humanos con experiencias, intuiciones, y no dependientes de "garbage in" para dar una buena respuesta.
La clave del futuro creo que está en la especialización.
Gracias por este artículo Simón.
Estoy de acuerdo con tu comentario sobre usar criptografía para poder distinguir quien es humano y quien no.
Uno de esos sistemas criptograficos también usa hardware para confirmar "humanidad" antes de darte un token para que pueda ser usado para acceder a plataformas o crear contenido.
Esto quiere decir que podríamos usar un sistemas de identificación y autenticación "sólo para humanos" que valide la humanidad de la persona que crea el contenido y así saber distinguidla de forma fácil del contenido de IA.
Otra cosa es que el humano luego use IA para crear contenido, pero sería pegarse un tiro en el pie porque ya perdería el "toque especial" de ese humano.
Un ejemplo de una empresa que está usando crypto y sistemas hardware de verificación de humanidad es Worldcoin (https://worldcoin.org/)
Un libro muy bueno que habla sobre esta co-existencia de crypto y AI es "Read. Write. Own" de Chris Dixon (https://readwriteown.com) por si alguien quiere profundizar