


Construyendo agentes eficaces
¿Qué son los agentes IA? ¿Cuándo (y cuándo no) utilizarlos? Frameworks, componentes básicos, workflows y casos de uso.

Anthropic, creador de Claude, publicó a mediados de diciembre el mejor artículo sobre agentes IA que he leído: Building effective agents. Aunque su público objetivo son desarrolladores, el texto es fácil de seguir y ofrece excelentes descripciones y aplicaciones prácticas de estos sistemas. Tan es así, que he invertido unas cuántas horas en traducirlo para ponerlo a disposición del público hispano-hablante. ¡Disfrutadlo!
Durante el último año, hemos trabajado con docenas de equipos creando agentes basados en grandes modelos del lenguaje (LLMs) en diferentes industrias. De manera consistente, las implementaciones más exitosas no utilizaban frameworks complejos ni librerías especializadas, sino que se basaban en patrones simples y componibles.
En este artículo, compartimos lo que hemos aprendido trabajando con nuestros clientes y creando agentes nosotros mismos, y damos consejos prácticos para que los desarrolladores creen agentes eficaces.
¿Qué son los agentes?
“Agente" se puede definir de varias maneras. Algunos clientes los definen como sistemas completamente autónomos que operan de forma independiente durante períodos prolongados, utilizando diversas herramientas para realizar tareas complejas. Otros utilizan el término para describir implementaciones más prescriptivas que siguen flujos de trabajo predefinidos. En Anthropic, categorizamos todas estas variaciones como sistemas agénticos, pero hacemos una distinción arquitectónica importante entre workflows y agentes:
Los workflows son sistemas donde los LLMs y las herramientas se orquestan vía código.
Los agentes, por su lado, son sistemas donde los LLMs dirigen dinámicamente sus propios procesos y uso de herramientas, manteniendo el control sobre cómo realizan las tareas.
A continuación, analizaremos en detalle ambos tipos de sistemas de agentes. En el Apéndice 1 (“Agentes en la práctica”), describimos dos ámbitos en los que los clientes han encontrado valor en el uso de este tipo de sistemas.
Cuándo (y cuándo no) utilizar agentes
Al crear aplicaciones con LLMs, recomendamos buscar la solución más simple posible y aumentar la complejidad solo cuando sea necesario. Esto podría significar no crear sistemas de agentes en absoluto. Los sistemas de agentes a menudo sacrifican latencia y coste por un mejor rendimiento de las tareas. Debes considerar cuándo este intercambio tiene sentido.
Cuando el incremento de complejidad está justificado, los workflows ofrecen previsibilidad y coherencia para tareas bien definidas, mientras que los agentes son la mejor opción cuando se necesita flexibilidad y toma de decisiones basada en modelos a gran escala. Sin embargo, para muchas aplicaciones, suele ser suficiente optimizar llamadas LLM individuales con recuperación (retrieval) y añadiendo ejemplos al contexto.
Cuándo y cómo utilizar frameworks
Existen muchos frameworks que facilitan la implementación de sistemas de agentes, entre ellos:
LangGraph de LangChain.
Amazon Bedrock AI Agent framework.
Rivet, un generador de flujos de trabajo LLM con interfaz gráfica de usuario de estilo arrastrar y soltar.
Vellum, otra herramienta con interfaz gráfica para crear y probar flujos de trabajo complejos.
Estos frameworks facilitan comenzar un proyecto al simplificar las tareas estándar de bajo nivel, como llamar a los LLM, definir y analizar herramientas y encadenar llamadas. Sin embargo, a menudo crean capas adicionales de abstracción que pueden oscurecer las instrucciones (prompts) y respuestas subyacentes, lo que dificulta su depuración. También pueden hacer que resulte tentador agregar complejidad cuando una configuración más sencilla sería suficiente.
Sugerimos que los desarrolladores comiencen por utilizar las API de los LLM directamente: muchos patrones se pueden implementar en unas pocas líneas de código. Si utilizas un framework, asegúrate de comprender el código subyacente. Las suposiciones incorrectas sobre lo que sucede internamente son una fuente común de errores para los usuarios.
Consulta nuestro libro de recetas para ver algunos ejemplos de implementaciones.
Componentes básicos, workflows y agentes
En esta sección, exploraremos los patrones comunes de los sistemas de agentes que hemos visto en producción. Comenzaremos con nuestro componente básico (el LLM aumentado) e incrementaremos progresivamente la complejidad, desde flujos de trabajo compositivos simples hasta agentes autónomos.
Componente básico: El LLM ampliado
El componente básico de los sistemas de agentes es un LLM mejorado con funciones de recuperación, herramientas y memoria. Nuestros modelos actuales pueden utilizar activamente estas capacidades: generar sus propias consultas de búsqueda, seleccionar las herramientas adecuadas y determinar qué información retener.
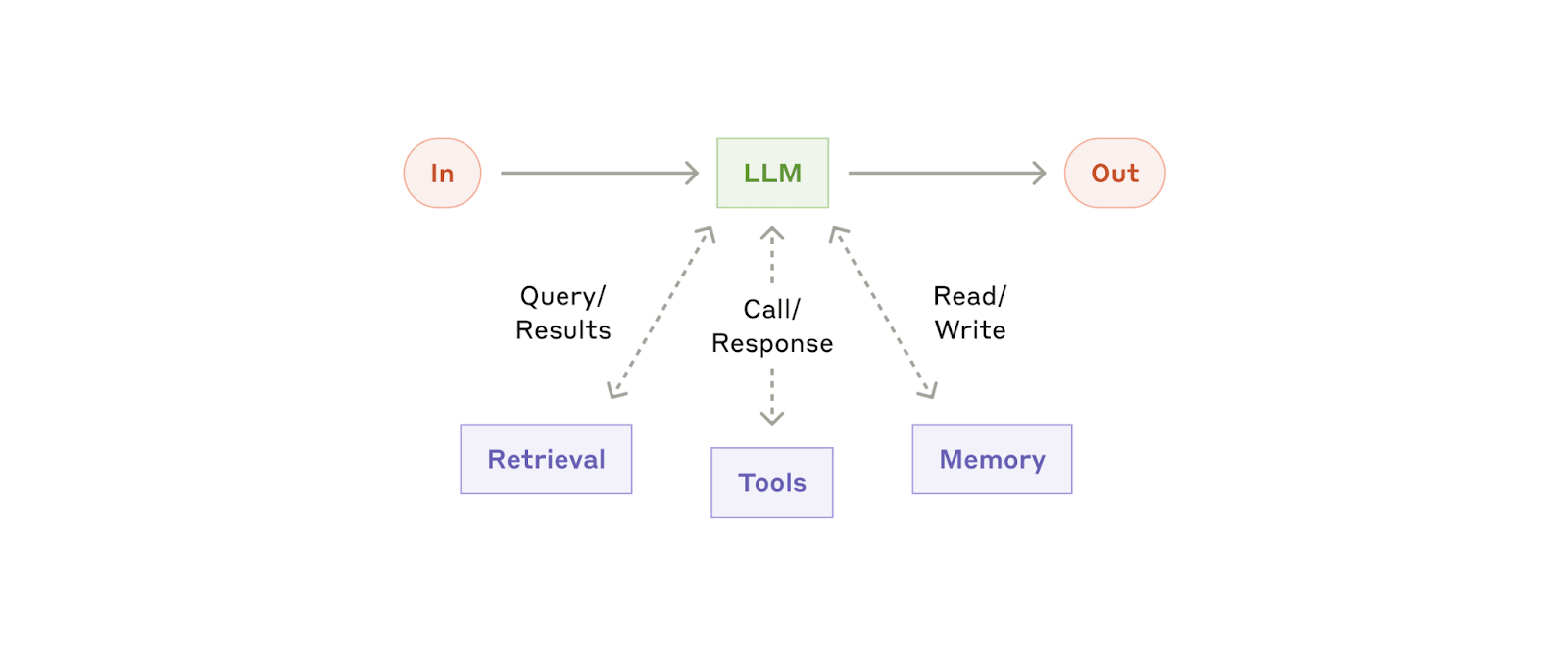
Recomendamos centrarse en dos aspectos clave de la implementación: adaptar estas capacidades a su caso de uso específico y garantizar que proporcionen una interfaz sencilla y bien documentada para tu LLM. Si bien hay muchas formas de implementar estas mejoras, una de ellas es a través de nuestro Model Context Protocol lanzado recientemente, que permite a los desarrolladores integrarse con un ecosistema en crecimiento de herramientas de terceros con una sencilla implementación.
Durante el resto de esta publicación, asumiremos que cada llamada al LLM tiene acceso a estas capacidades aumentadas.
Workfkow: encadenamiento de prompts (prompt chaining”)
El encadenamiento de prompts descompone una tarea en una secuencia de pasos, donde cada petición LLM procesa el resultado de la anterior. Podemos agregar comprobaciones programáticas ("gate" en el diagrama a continuación) en cualquier paso intermedio para asegurarnos de que el proceso sigue su curso.
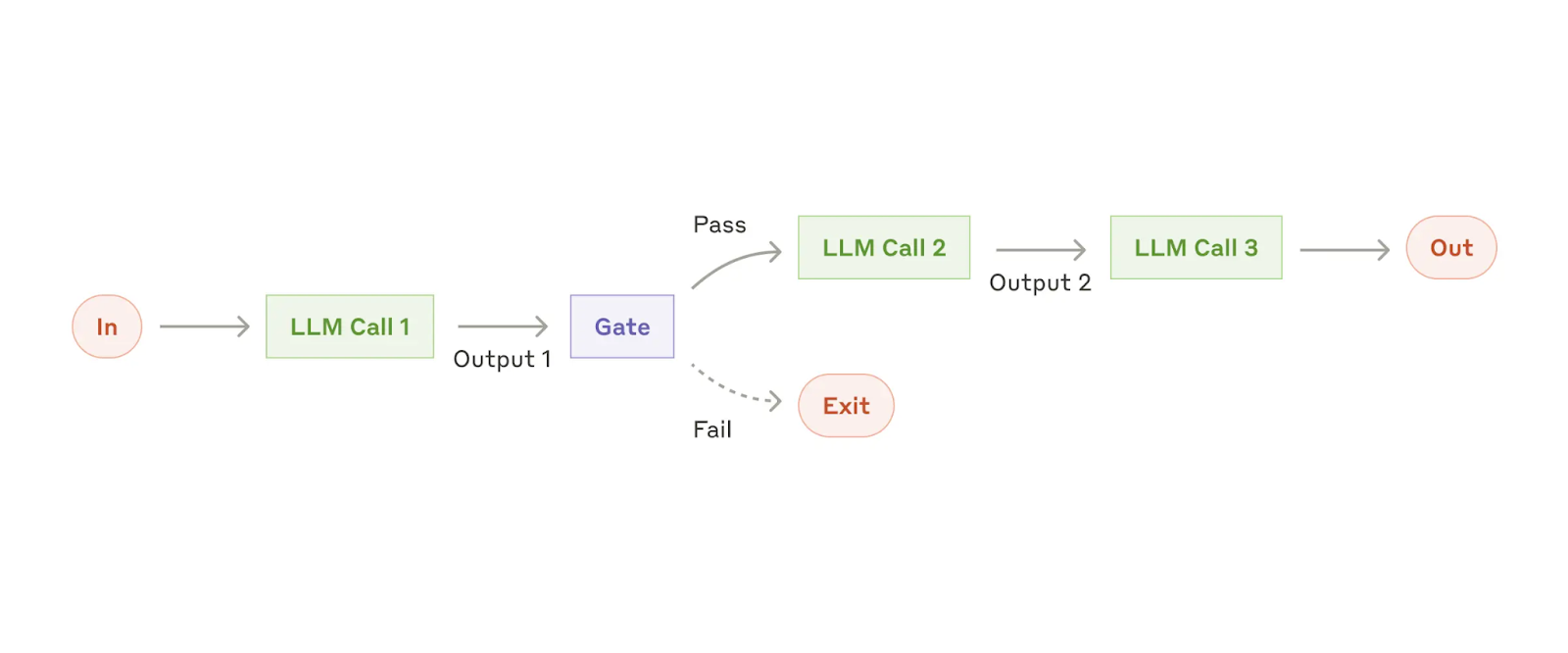
Cuándo utilizar este workflow: Este workflow es ideal para situaciones en las que la tarea se puede descomponer de forma fácil y clara en subtareas fijas. El objetivo principal es compensar la latencia con una mayor precisión, haciendo que cada petición LLM sea una tarea más sencilla.
Ejemplos en los que el encadenamiento de prompts resulta útil:
Generar un texto de marketing y luego traducirlo a un idioma diferente.
Escribir un esquema de un documento, verificar que el esquema cumple ciertos criterios y luego escribir el documento basándose en el esquema.
Workflow: enrutamiento
El enrutamiento clasifica una entrada y la dirige a una tarea especializada a continuación. Este workflow permite separar ámbitos y crear prompts más especializados. Sin este workflow, la optimización de un tipo de entrada puede perjudicar el rendimiento de otras.
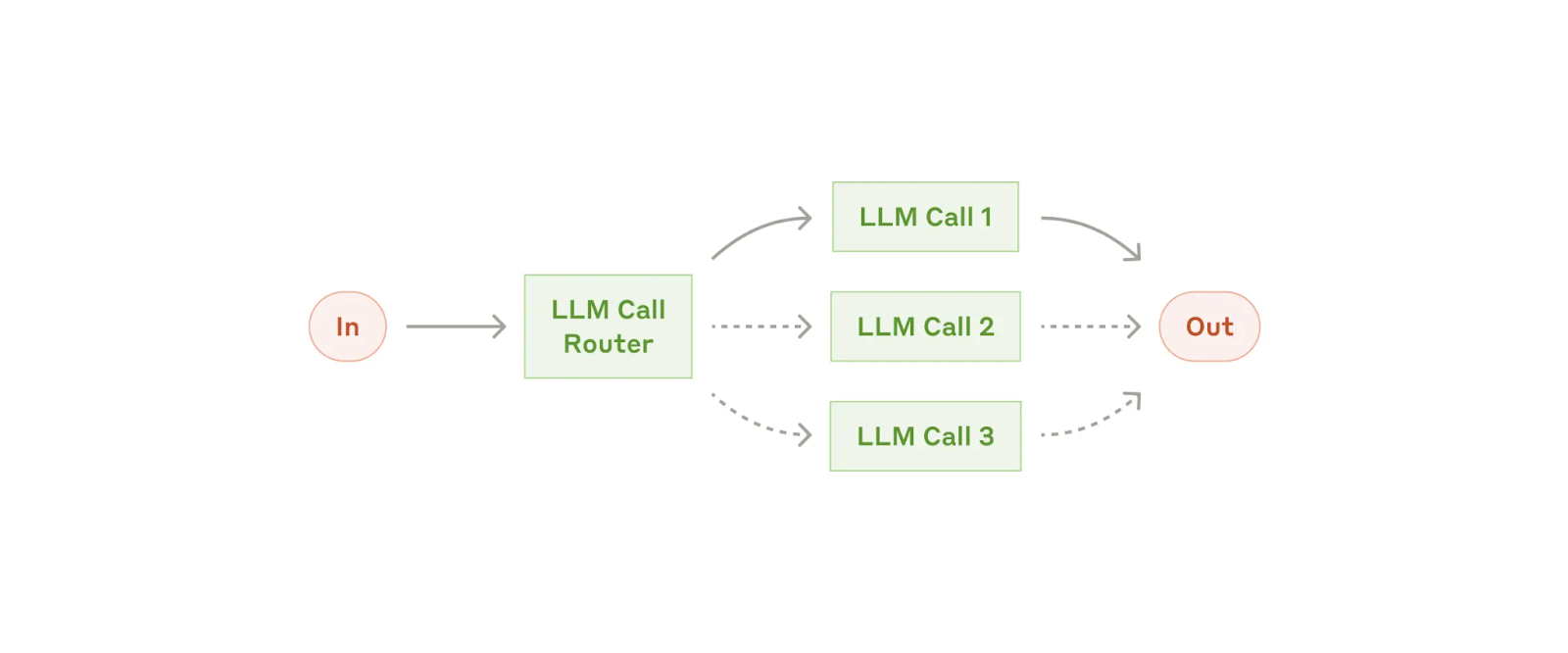
Cuándo utilizar este workflow: el enrutamiento funciona bien para tareas complejas donde hay categorías distintas que se manejan mejor por separado y donde la clasificación se puede manejar con precisión, ya sea mediante un LLM o un modelo/algoritmo de clasificación más tradicional.
Ejemplos en los que el enrutamiento es útil:
Redireccionar distintos tipos de consultas de atención al cliente (preguntas generales, solicitudes de reembolso, soporte técnico) a diferentes procesos posteriores, prompts y herramientas.
Enrutar preguntas fáciles/comunes a modelos más pequeños como Claude 3.5 Haiku y preguntas difíciles/inusuales a modelos más capaces como Claude 3.5 Sonnet para optimizar velocidad y costes.
Workflow: Paralelización
En ocasiones, los LLM pueden trabajar simultáneamente en una tarea y agregar sus resultados programáticamente. Este workflow, la paralelización, se manifiesta en dos variantes clave:
Seccionamiento: dividir una tarea en subtareas independientes que se ejecutan en paralelo.
Votación: ejecutar la misma tarea varias veces para obtener resultados diversos.
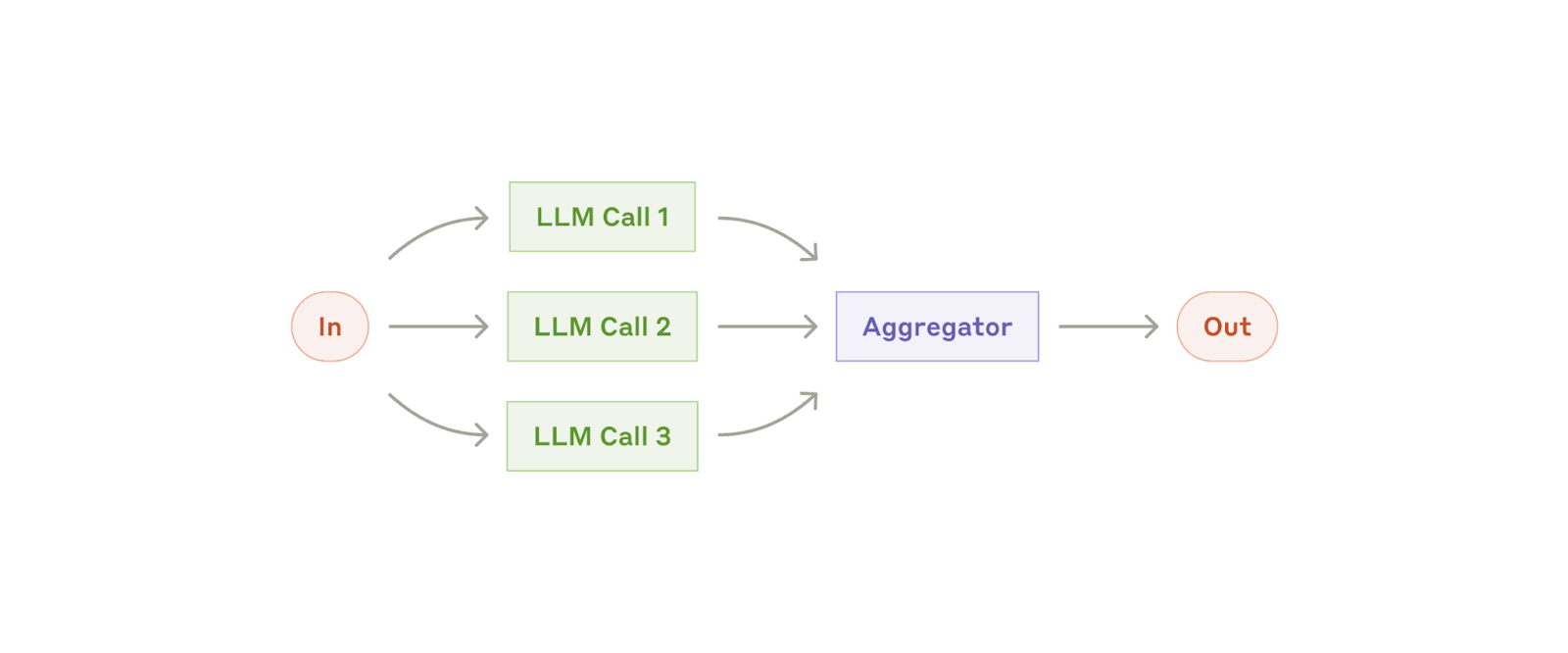
Cuándo utilizar este workflow: la paralelización es eficaz cuando las subtareas divididas se pueden paralelizar para lograr mayor velocidad o cuando se necesitan múltiples perspectivas o intentos para obtener resultados más confiables. En el caso de tareas complejas con múltiples intentos, los LLM generalmente funcionan mejor cuando cada intento se maneja mediante una llamada LLM independiente, lo que permite centrar la atención en cada aspecto específico.
Ejemplos en los que la paralelización es útil:
Seccionamiento:
Implementar guardarraíles donde una instancia de modelo procesa las consultas de los usuarios mientras que otra las filtra para detectar contenido o solicitudes inapropiadas. Esto suele funcionar mejor que utilizar la misma petición LLM para gestionar el guardarraíl y la respuesta principal.
Automatizar evaluaciones del rendimiento del LLM, donde cada petición evalúa un aspecto diferente del rendimiento del modelo en una solicitud determinada.
Votación:
Revisión de un fragmento de código en busca de vulnerabilidades, donde varios indicadores diferentes revisan y marcan el código si encuentran un problema.
Evaluar si un determinado contenido es inapropiado, a través de múltiples prompts que evalúan diferentes aspectos o requieren diferentes umbrales de votación para equilibrar los falsos positivos y negativos.
Workflow: orquestador-trabajadores
En el workflow orquestador-trabajadores, un LLM central divide dinámicamente las tareas, las delega a los LLM trabajadores (workers) y sintetiza sus resultados.
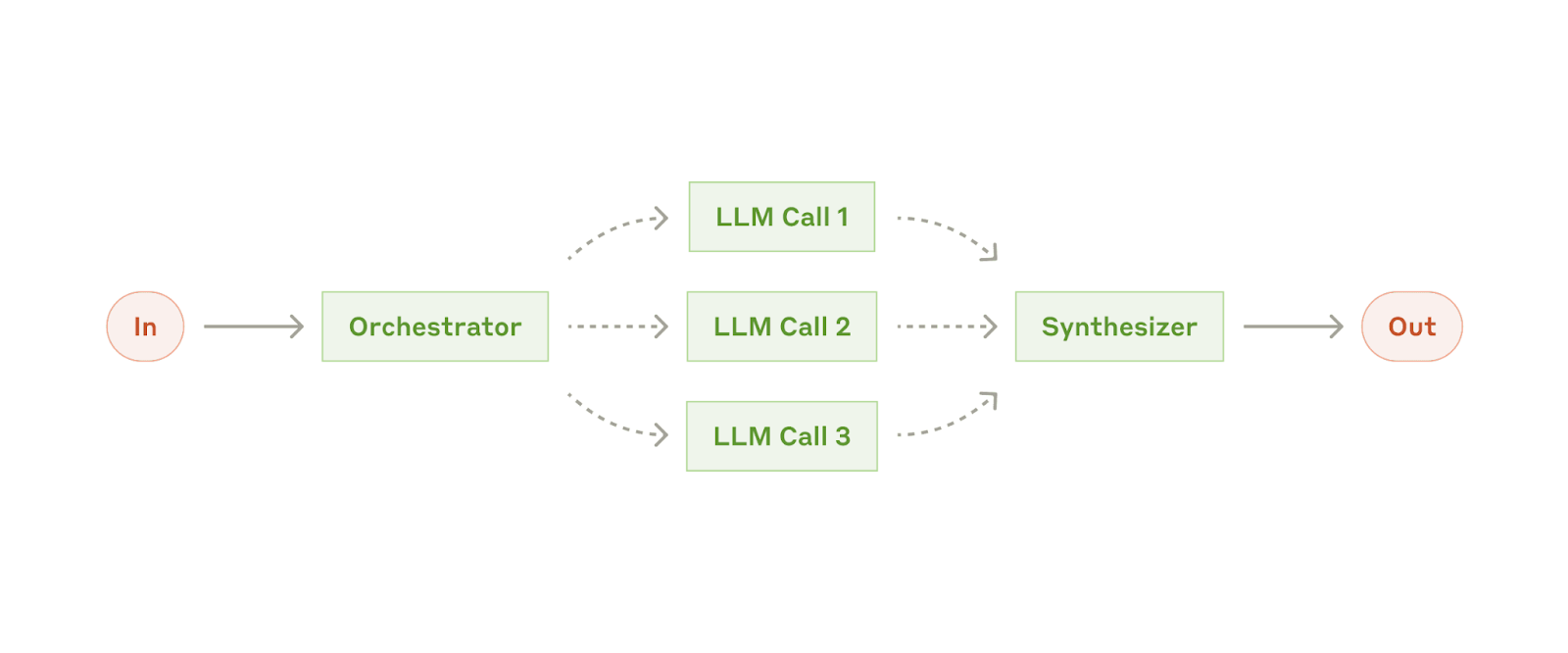
Cuándo utilizar este workflow: Este workflow es adecuado para tareas complejas en las que no se pueden predecir las subtareas necesarias (al programar, por ejemplo, la cantidad de archivos que se deben modificar y la naturaleza del cambio en cada archivo probablemente dependan de la tarea). Si bien es topográficamente similar, la diferencia clave con la paralelización es su flexibilidad: las subtareas no están predefinidas, sino que las determina el orquestador en función de la entrada específica.
Ejemplos en los que orquestador-trabajadores resulta útil:
Programación de productos que realizan cambios complejos en múltiples archivos cada vez.
Tareas de búsqueda que impliquen la recopilación y análisis de información de múltiples fuentes para encontrar una posible información relevante.
Workflow: evaluador-optimizador
En el workflow del evaluador-optimizador, una llamada LLM genera una respuesta mientras que otra proporciona evaluación y retroalimentación en un bucle.
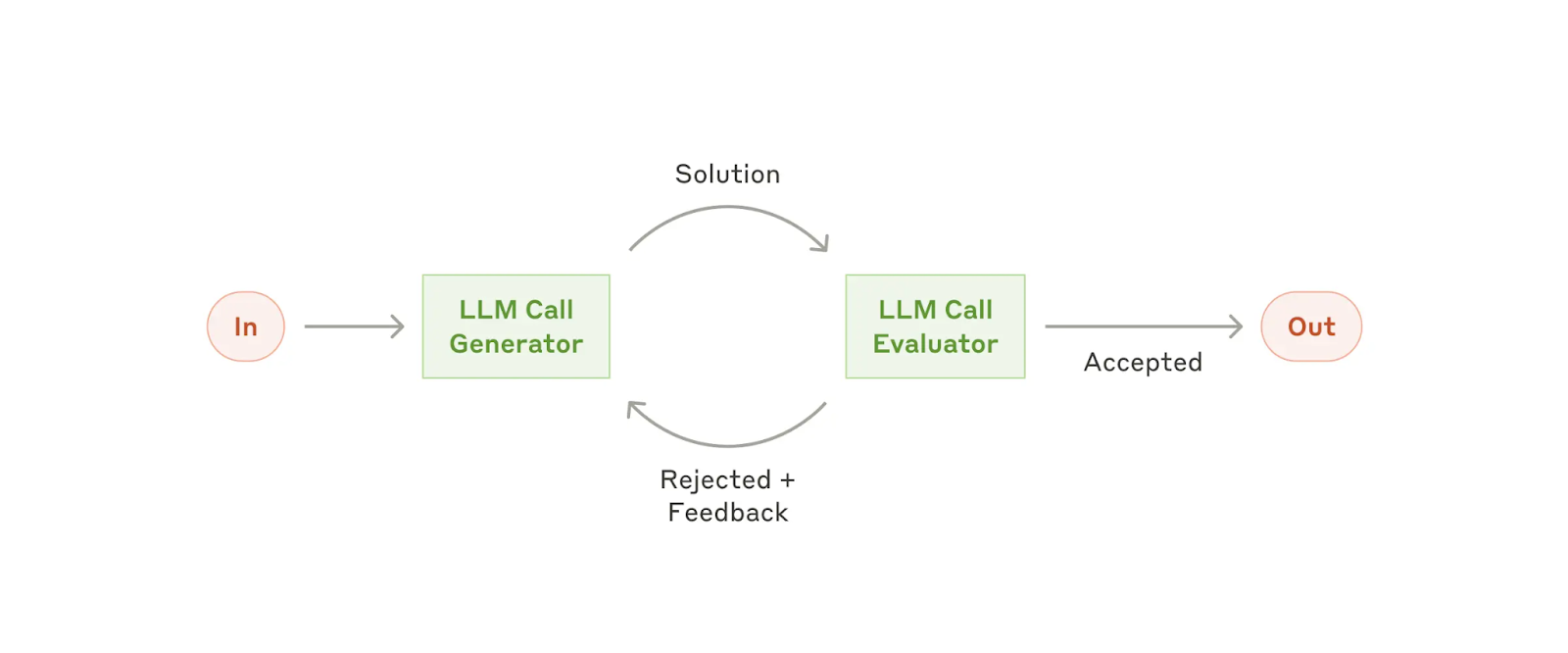
Cuándo utilizar este workflow: Este workflow es particularmente eficaz cuando tenemos criterios de evaluación claros y el refinamiento iterativo proporciona un valor medible. Las dos señales de que se ajusta bien son, en primer lugar, que las respuestas del LLM se puedan mejorar de forma demostrable cuando son retroalimentadas por un humano; y, en segundo lugar, que el LLM pueda proporcionar dicha retroalimentación. Esto es análogo al proceso de escritura iterativa por el que podría pasar un escritor humano al producir un documento final.
Ejemplos en los que el evaluador-optimizador es útil:
Traducción literaria en la que hay matices que el traductor LLM podría no captar inicialmente, pero donde un evaluador LLM puede proporcionar críticas útiles.
Tareas de búsqueda complejas que requieren varias rondas de búsqueda y análisis para recopilar información exhaustiva, en las que el evaluador decide si está justificado realizar más búsquedas.
Agentes
Los agentes están apareciendo en producción a medida que los LLM maduran en capacidades clave: comprender entradas complejas, participar en razonamiento y planificación, usar herramientas de manera fiable y recuperarse de errores. Los agentes comienzan su trabajo a partir de un comando, o una discusión interactiva, con un usuario humano. Una vez que la tarea está clara, los agentes planifican y operan de manera independiente, con la posibilidad de volver al humano para obtener más información o juicio. Durante la ejecución, es crucial que los agentes obtengan "verdad fundamental" del entorno en cada paso (como los resultados de la petición a una herramienta o la ejecución de código) para evaluar su progreso. Después, los agentes pueden pausarse para recibir comentarios humanos en los puntos de control o cuando encuentran bloqueos. La tarea a menudo termina al completarse, pero también es común incluir condiciones de detención (como un número máximo de iteraciones) para mantener el control.
Los agentes pueden manejar tareas sofisticadas, pero su implementación suele ser sencilla. Por lo general, son solo LLM que utilizan herramientas basadas en la retroalimentación del entorno en un bucle. Por lo tanto, es fundamental diseñar conjuntos de herramientas y su documentación de manera clara y reflexiva. Ampliamos las mejores prácticas para el desarrollo de herramientas en el Apéndice 2 ("Prompt engineering sobre herramientas").
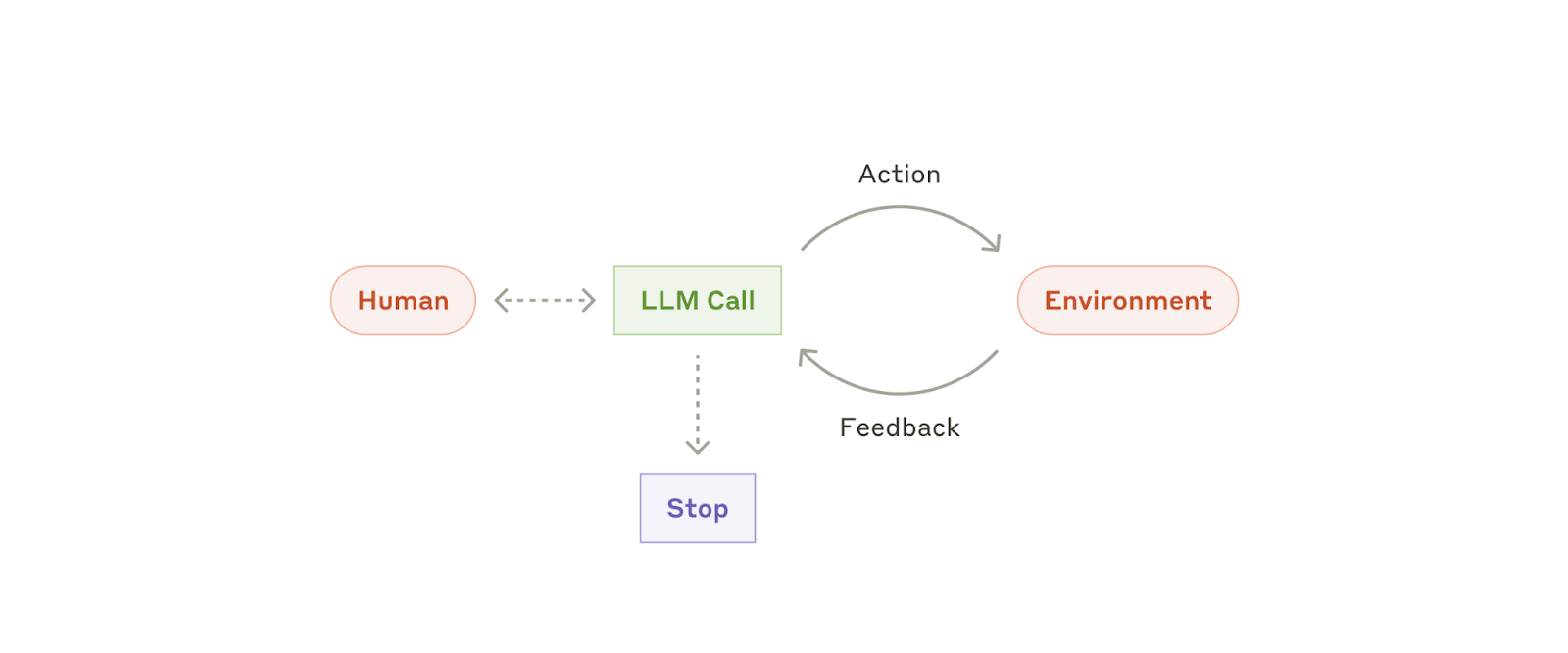
Cuándo utilizar agentes: Los agentes se pueden utilizar para problemas abiertos en los que es difícil o imposible predecir la cantidad de pasos necesarios y en los que no se puede programar una ruta fija. El LLM potencialmente funcionará durante muchas iteraciones y se debe tener cierto nivel de confianza en su toma de decisiones. La autonomía de los agentes los hace ideales para escalar tareas en entornos confiables.
La naturaleza autónoma de los agentes implica mayores costes y la posibilidad de errores compuestos. Recomendamos realizar pruebas exhaustivas en entornos aislados, junto con medidas de seguridad adecuadas.
Ejemplos en los que los agentes son útiles:
Los siguientes ejemplos son de nuestras propias implementaciones:
Un agente de programación para resolver tareas de SWE-bench, que implican ediciones de muchos archivos en función de la descripción de una tarea.
Nuestra implementación de “computer use”, donde Claude utiliza el ordenador para realizar tareas.

Combinando y personalizando estos patrones
Estos componentes básicos no son prescriptivos. Son patrones comunes que los desarrolladores pueden moldear y combinar para adaptarse a diferentes casos de uso. La clave del éxito, como con cualquier característica de LLM, es medir el rendimiento e iterar las implementaciones. Reiteramos: sólo se debe considerar la posibilidad de añadir complejidad cuando se demuestre que mejora los resultados.
Resumen
El éxito en el espacio de los LLMs no consiste en construir el sistema más sofisticado. Se trata de construir el sistema más adecuado a nuestras necesidades. Empieza con prompts sencillos, optimízalos con una evaluación exhaustiva y añade sistemas agénticos de varios pasos solo cuando las soluciones más sencillas se queden cortas.
Al implementar agentes, intentamos seguir tres principios fundamentales:
Mantener la simplicidad en el diseño del agente.
Priorizar la transparencia mostrando explícitamente los pasos de planificación del agente.
Diseñar cuidadosamente su interfaz agente-computadora (ACI) a través de una exhaustiva documentación y pruebas de las herramientas.
Los frameworks pueden ayudarte a empezar rápidamente, pero no dudes en reducir las capas de abstracción y construir con componentes básicos cuando pases a producción. Siguiendo estos principios, puedes crear agentes que no sólo sean potentes, sino también fiables, mantenibles y en los que confíen sus usuarios.
Agradecimientos
Escrito por Erik Schluntz y Barry Zhang. Este trabajo se basa en nuestra experiencia en la creación de agentes en Anthropic y en los valiosos conocimientos que comparten nuestros clientes, por los que estamos profundamente agradecidos.
Apéndice 1: Agentes en la práctica
Nuestro trabajo con clientes ha revelado dos aplicaciones particularmente prometedoras para los agentes de IA que demuestran el valor práctico de los patrones analizados anteriormente. Ambas aplicaciones ilustran cómo los agentes agregan el mayor valor a las tareas que requieren tanto conversación como acción, tienen criterios de éxito claros, permiten ciclos de retroalimentación e integran una supervisión humana significativa.
A. Atención al cliente
La atención al cliente combina interfaces de chatbot familiares con capacidades mejoradas a través de la integración de herramientas. Esto es una opción natural para agentes abiertos (open-ended) porque:
Las interacciones de soporte siguen naturalmente un flujo de conversación aunque requieren acceso a información y acciones externas.
Se pueden integrar herramientas para extraer datos de clientes, historial de pedidos y entradas del centro de soporte.
Acciones como emitir reembolsos o actualizar tickets se pueden gestionar de forma programática.
El éxito se puede medir claramente a través de resoluciones definidas por el usuario.
Varias empresas han demostrado la viabilidad de este enfoque a través de modelos de precio basados en el uso que cobran sólo por cada caso resuelto con éxito, lo que demuestra confianza en la eficacia de sus agentes.
B. Agentes de programación
El espacio de desarrollo de software ha demostrado un potencial notable para las funciones LLM, con capacidades que evolucionan desde autocompletar código hasta la resolución autónoma de problemas. Los agentes son particularmente eficaces porque:
Las soluciones basadas en código son verificables a través de pruebas automatizadas.
Los agentes pueden iterar sobre soluciones utilizando los resultados de las pruebas como retroalimentación.
El espacio del problema está bien definido y estructurado.
La calidad del resultado se puede medir objetivamente.
En nuestra propia implementación, los agentes pueden resolver problemas reales de GitHub en SWE-bench Verified basándose únicamente en la descripción del pull request. Sin embargo, mientras que las pruebas automatizadas ayudan a verificar la funcionalidad, la revisión humana sigue siendo crucial para garantizar que las soluciones se alineen con los requisitos más amplios del sistema.
Apéndice 2: Prompt engineering sobre herramientas
Independientemente del sistema que estés construyendo, las herramientas probablemente serán una parte importante de tu agente. Las herramientas permiten a Claude interactuar con servicios externos y APIs especificando su estructura y definición exactas en nuestra API. Cuando Claude responde, incluirá un bloque de uso de herramientas en la respuesta de la API si planea utilizar una. Las definiciones y especificaciones de herramientas deben recibir la misma atención de prompt engineering que los prompts generales. En este breve apéndice, describimos cómo realizar prompt engineering sobre tus herramientas.
A menudo, existen varias formas de especificar la misma acción. Por ejemplo, puedes especificar la edición de un archivo escribiendo un diff o reescribiendo el archivo completo. Para obtener una salida estructurada, puedes devolver el código vía Markdown o JSON. En ingeniería de software, estas diferencias son cosméticas e intercambiables. Sin embargo, algunos formatos son mucho más complicados para un LLM que otros. Escribir un diff requiere saber cuántas líneas están cambiando en el encabezado del fragmento antes de escribir el nuevo código. Escribir código JSON (en comparación con Markdown) requiere un escape adicional de nuevas líneas y comillas.
Nuestras sugerencias para decidir los formatos de herramientas son las siguientes:
Dale al modelo suficientes tokens para que "piense" antes de que se arrincone a sí mismo.
Mantén el formato cercano a lo que el modelo ha visto ocurrir naturalmente en Internet.
Asegúrate de que no haya "sobrecarga" de formato, como tener que mantener un recuento preciso de miles de líneas o escapar cadenas.
Una regla general es pensar en cuánto esfuerzo se dedica a las interfaces hombre-computadora (HCI) y planificar invertir la misma cantidad de esfuerzo en la creación de buenas interfaces agente-computadora (ACI). A continuación, se ofrecen algunas ideas sobre cómo hacerlo:
Ponte en el lugar del modelo. ¿Es obvio cómo utilizar esta herramienta, según la descripción y los parámetros, o necesitas pensarlo detenidamente? Si es así, probablemente también sea así para el modelo. Una buena definición de una herramienta suele incluir ejemplos de uso, casos extremos, requisitos de formato de entrada y límites claros con respecto a otras herramientas.
¿Se pueden cambiar los nombres o las descripciones de los parámetros para que sean más obvios? Piensa en esto como si estuvieras escribiendo documentación para un desarrollador junior de su equipo. Esto es especialmente importante cuando se utilizan muchas herramientas similares.
Prueba cómo el modelo utiliza sus herramientas: ejecuta muchas entradas de ejemplo en nuestro banco de pruebas para ver qué errores comete el modelo, e itera.
Utiliza herramientas de tipo poka-yoke. Cambia los argumentos para que sea más difícil cometer errores.
Al crear nuestro agente para SWE-bench, dedicamos más tiempo a optimizar nuestras herramientas que el prompt general. Por ejemplo, descubrimos que el modelo cometía errores con herramientas que usaban rutas de archivo relativas después de que el agente se hubiera movido del directorio raíz. Para solucionar esto, cambiamos la herramienta para que siempre requiriese rutas de archivo absolutas y descubrimos que el modelo usaba este método sin problemas.
top!
Buenísimo post 👏👏