


Cómo sacar el máximo partido a los modelos IA de razonamiento
Guía de buenas prácticas de OpenAI sobre cómo utilizar modelos de razonamiento. Diferencias frente a los modelos GPT. Flujos de trabajo IA y consejos sobre prompting.

¿Sabes cuándo utilizar un LLM de razonamiento y cuándo no? Si eres como yo, probablemente optarás por el modelo que entiendas más potente, independientemente de su tipo.
En mi caso, por ejemplo, cuando veo el desplegable de ChatGPT, es difícil no elegir siempre el modelo o1 pro, que además, lleva la etiqueta “Best at reasoning”. ¿El mejor? Pues ahí que voy.
Sin embargo, los modelos de razonamiento no tienen por qué ser siempre la mejor opción, especialmente si tienes en mente construir sistemas utilizando LLMs. En el post de hoy, hablaremos de las diferencias entre modelos de razonamiento y modelos generales, y cómo sacar el máximo partido a los primeros.
Diferencias entre los modelos de razonamiento y los modelos GPT
OpenAI, en la documentación de su API, tiene un excelente artículo sobre las mejores prácticas en relación con modelos de razonamiento. En el mismo, describe las diferencias entre sus distintos modelos:
Hemos entrenado a nuestros modelos de la serie o («los planificadores») para que piensen durante más tiempo y con mayor intensidad en tareas complejas, lo que les permite elaborar estrategias, planificar soluciones a problemas complejos y tomar decisiones basadas en grandes volúmenes de información ambigua. Estos modelos también pueden ejecutar tareas con gran exactitud y precisión, lo que los hace ideales para ámbitos que de otro modo requerirían un experto humano, como las matemáticas, la ciencia, la ingeniería, los servicios financieros y los servicios jurídicos.
Por otro lado, nuestros modelos GPT («los caballos de batalla»), más rentables y de menor latencia, están diseñados para una ejecución sencilla. Una aplicación puede utilizar modelos de la serie o para planificar la estrategia de resolución de un problema y utilizar modelos GPT para ejecutar tareas específicas, sobre todo cuando la velocidad y el coste son más importantes que la precisión perfecta.
Más adelante, explican cómo elegir entre uno u otro en función de qué es más importante para tu caso de uso:
¿Cómo elegir entre modelos?
Velocidad y coste → Los modelos GPT son más rápidos y suelen costar menos
Ejecución de tareas bien definidas → Los modelos GPT manejan bien tareas definidas explícitamente
Precisión y fiabilidad → Los modelos de la “serie o” son fiables a la hora de tomar decisiones
Resolución de problemas complejos → Los modelos de la “serie o” trabajan a través de la ambigüedad y la complejidad
Si la velocidad y el coste son los factores más importantes y tu caso de uso se compone de tareas sencillas y bien definidas, entonces nuestros modelos GPT serán los más adecuados. Sin embargo, si la precisión y la fiabilidad son los factores más importantes y tienes que resolver un problema muy complejo de varios pasos, es probable que nuestros modelos de la serie o sean los más adecuados.
En definitiva, podríamos decir que cuanta más incertidumbre haya en una tarea, más se beneficiará de un modelo de razonamiento. Y, a la inversa: utilizar uno de estos modelos para abordar una tarea sencilla es una magnífica forma de quemar dinero. Lo que vendría a ser matar moscas a cañonazos.
Esta es la razón, por ejemplo, por la que OpenAI y otros ponen límites al número de consultas que puedes lanzar contra determinados modelos. Los costes pueden ser de un orden de magnitud superior.
El problema, para OpenAI, por supuesto, es que el nombre de sus modelos y la interfaz donde los seleccionas parecen diseñados por su peor enemigo. Pero es que, que OpenAI tenga una interfaz de usuario es en sí un accidente. Era una compañía que nació enfocada en servir sus modelos a través de una API para terceros, pero entonces a alguien se le ocurrió lanzar ChatGPT, y el resto es historia. Ben Thompson lo argumenta en The Accidental Consumer Tech Company.
Sam Altman, de hecho, avanzando hace unos días el roadmap de OpenAI, reconocía abiertamente que su oferta de producto era un desastre, y dejaba caer que GPT5 lo solucionará porque evitará tener que escoger. O, dicho de otra forma, GPT5 evaluará primero nuestra consulta y se encargará de enrutarla al modelo más adecuado:
We want AI to “just work” for you; we realize how complicated our model and product offerings have gotten.
We hate the model picker as much as you do and want to return to magic unified intelligence.
We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model.
After that, a top goal for us is to unify o-series models and GPT-series models by creating systems that can use all our tools, know when to think for a long time or not, and generally be useful for a very wide range of tasks.
In both ChatGPT and our API, we will release GPT-5 as a system that integrates a lot of our technology, including o3. We will no longer ship o3 as a standalone model.
¿Por qué es importante entender cómo funcionan los modelos?
Si eres un usuario final que paga una suscripción fija al mes, la realidad es que el coste de cada consulta te es indiferente. Sin embargo, si quieres crear sistemas y productos que utilicen LLMs, lo más probable es que quieras optimizar tus costes y latencias, por lo que saber escoger el mejor modelo para cada tarea es imprescindible.
Por ejemplo, OpenAI proporciona en su guía un ejemplo de flujo de trabajo IA en el que distintos modelos interactúan entre sí para resolver una petición típica a un servicio de atención al cliente.
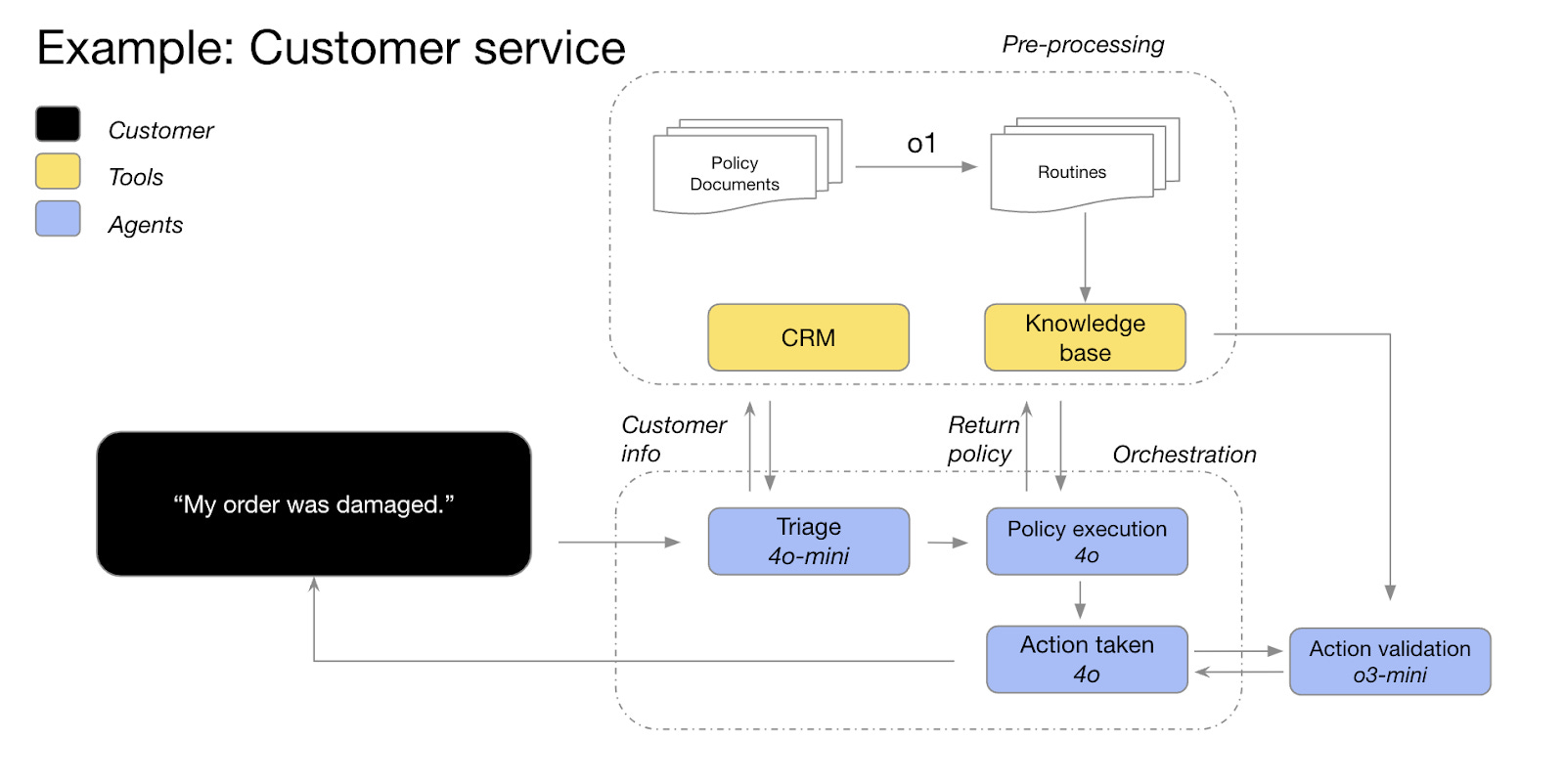
En ese ejemplo:
El modelo o1 se utiliza para generar una serie de rutinas en base a la documentación del servicio de atención al cliente de la empresa.
Los modelos 4o se utilizan para hacer triaje de la consulta del usuario, comprobar si cumple los requisitos para una devolución, y tomar la decisión.
Finalmente, otro modelo de razonamiento, o3-mini, se utiliza para validar que la decisión es la correcta.
Cómo interactuar con un modelo de razonamiento
Otro aspecto interesante de los modelos de razonamiento es que la técnica de prompting es distinta a la de los modelos GPT. Por ejemplo, OpenAI recomienda:
Las instrucciones deben ser sencillas y directas: los modelos son excelentes comprendiendo y respondiendo a instrucciones breves y claras.
Evita los prompts de tipo chain-of-thought: Dado que estos modelos razonan internamente, no es necesario pedirles que "piensen paso a paso" o "expliquen su razonamiento".
Utiliza delimitadores para mayor claridad: Utiliza delimitadores como markdown, etiquetas XML y títulos de sección para indicar claramente las distintas partes de la entrada y ayudar al modelo a interpretar las diferentes secciones de forma adecuada.
Prueba primero prompts sin ejemplos (zero shot), luego con algunos (few shot) sólo si es necesario: Los modelos de razonamiento no suelen necesitar ejemplos para producir buenos resultados, así que intenta escribir primero prompts sin ejemplos. Si tienes requisitos más complejos, puede ser útil incluir algunos ejemplos de entradas y salidas deseadas en el prompt. Sólo asegúrate de que los ejemplos coincidan con las instrucciones, ya que las discrepancias entre ambos pueden producir malos resultados.
Proporciona directrices específicas: Si hay formas en las que explícitamente quieres restringir la respuesta del modelo (como "proponer una solución con un presupuesto inferior a 500 dólares"), describe explícitamente esas restricciones en el prompt.
Sé muy específico sobre tu objetivo final: En tus instrucciones, trata de dar parámetros muy específicos para lo que consideres una respuesta válida, y anima al modelo a seguir razonando e iterando hasta que coincida con tus criterios de éxito.
Conclusiones
El futuro de los modelos de lenguaje apunta hacia sistemas más integrados e inteligentes que simplificarán las decisiones técnicas. Sin embargo, mientras ese día llega, es crucial entender y saber utilizar las herramientas a nuestra disposición.
Espero que el artículo de hoy os haya servido para entender un poco mejor las posibilidades de los distintos modelos y cómo sacarles el máximo partido en vuestro día a día. A mí, personalmente me ha servido para ahorrar tiempo en mis interacciones diarias, evitando gastar tiempo y recursos de razonamiento en consultas sencillas.
Y, por supuesto, el ejemplo de un flujo de trabajo IA, también me ha servido para entender un poco más cómo se construyen estos sistemas, enlazando modelos de forma que podamos optimizar costes.
Por cerrar con una recomendación, si queréis ahondar más sobre el tema, OpenAI ofrece un curso gratuito de apenas una hora en DeepLearning.ai que me ha gustado bastante: Reasoning with o1. ¡Disfrutadlo!