


Los tres pilares de la Inteligencia Artificial
Una introducción a las bases de la Inteligencia Artificial. Machine Learning, Neural Networks y Deep Learning explicado para torpes. Casos de uso y modelos IA.

¿Puede una máquina pensar?". Esta pregunta, planteada por Alan Turing en 1950, dio inicio a la revolución de la Inteligencia Artificial. Desde un simple juego de damas capaz de aprender por sí mismo, hasta complejos sistemas que imitan el funcionamiento del cerebro humano, la IA ha recorrido un largo camino.
En el artículo de hoy, he querido profundizar en tres pilares fundamentales de la Inteligencia Artificial: Machine Learning, Neural Networks y Deep Learning.
Mi objetivo es que cualquiera que lo lea pueda tener una idea aproximada de cómo funcionan y se combinan estas tecnologías entre sí, pues son la base de toda la revolución de la Inteligencia Artificial Generativa que estamos viviendo.
Pero antes de meternos directamente en harina, haremos una pequeña introducción al término IA y qué representa en realidad.
Inteligencia Artificial: ¿Puede una máquina pensar?
Los orígenes del término Inteligencia Artificial se remontan a 1950. Alan Turing, el famoso matemático británico, iniciaba su famoso paper “Computing Machinery and Intelligence” de esta forma:
I propose to consider the question, ‘Can machines think?’ — Alan Turing
En el paper, Turing describía un test al que llamó “The imitation game”, que permitiría discernir si una máquina exhibía una inteligencia indistinguible de la de un humano.
La comunidad científica empezó a interesarse por la cuestión, y años más tarde, en 1952, Arthur Samuel, creó un juego de damas que es considerado el primer programa con capacidad de aprender.
En 1956, John McCarthy, profesor de matemáticas en Darmouth, reunió a un pequeño grupo de científicos con la idea de realizar un estudio de investigación sobre Inteligencia Artificial. Es la primera referencia que tenemos del uso del término, y se considera el punto de inicio del estudio de la disciplina.
¿Qué es? Hoy en día, la Inteligencia Artificial es una rama de la informática cuyo objetivo es desarrollar sistemas autónomos capaces de realizar tareas que típicamente requieren inteligencia humana como aprender, razonar y tomar decisiones.
¿Por qué es importante? La Inteligencia Artificial es importante porque permite aumentar la capacidad de resolver problemas a escala. En su ausencia, cada problema necesita de un experto o grupo de expertos que programe una solución específica para un problema dado.
Pero resulta que hay un infinito número de problemas pero un limitado número de expertos con las habilidades necesarias para resolverlos.
Con los suficientes datos, potencia de cálculo, y energía, la Inteligencia Artificial sería capaz de generar un experto a medida para cada problema.
Machine Learning: Aprendiendo desde los datos
¿Qué es? El Machine Learning es una rama de la Inteligencia Artificial que se centra en conseguir sistemas que aprendan de forma autónoma sin intervención humana.
¿Por qué es importante? Permite abordar problemas complejos y dinámicos que serían casi imposibles de programar mediante reglas fijas en un algoritmo clásico. Es la palanca que permitiría crear expertos a demanda sobre cualquier problema sobre el que tengamos la suficiente cantidad de datos.
¿Cómo lo hace? De una forma extremadamente simplificada, podríamos decir que los algoritmos de Machine Learning aprenden a base de prueba y error.
Un ejemplo clásico es el de entrenar a un cachorro. Si quieres conseguir que tu cachorro te de la patita, le recompensarás cuando lo haga bien y le corregirás cuando no lo haga.
Podemos entrenar un sistema con Machine Learning casi del mismo modo. Por ejemplo, si quisiéramos entrenar a un sistema para que identificara correos electrónicos potencialmente SPAM, lo haríamos así:
Le enseñamos un correo
Lo califica como SPAM o no (la primera vez, aleatoriamente)
Le premiamos si acierta o le corregimos si no lo hace
El sistema se ajusta internamente según la respuesta
Volvemos al primer paso
Así, con cada pasada, el sistema aprende a discriminar qué correos son legítimos y cuáles no.
Tipos de aprendizaje: Es importante destacar que hay tres tipos principales de aprendizaje de ML:
Supervised Learning: El sistema aprende a través de datos etiquetados. En nuestro ejemplo del SPAM, consistiría en inicializar el sistema con un conjunto de correos marcados marcados como SPAM o NO SPAM. De esta forma, este es capaz de evaluarse a sí mismo en el tercer paso sin intervención humana.
Unsupervised Learning: El sistema aprende de datos no etiquetados. Su objetivo es encontrar patrones y relaciones que no son evidentes, como por ejemplo, segmentar a clientes en grupos según su comportamiento. En este caso su función de evaluación se basaría en medidas de cohesión entre los miembros y separación de otros grupos.
Reinforcement Learning: El sistema aprende a través de prueba y error a través de su interacción con el entorno. Por ejemplo, AlphaGo, la IA desarrollada por Google Deepmind que batió al campeón mundial de Go, jugó contra sí mismo millones de veces, utilizando cada partida ganada o perdida como su función de recompensa para mejorarse a sí mismo.
Neural Networks: Imitando al cerebro humano
¿Qué son? Las Neural Networks, o redes neuronales, son una serie de algoritmos utilizados en Machine Learning que permiten identificar patrones y relaciones en conjuntos de datos.
¿Por qué son importantes? Las redes neuronales son capaces de identificar relaciones complejas en situaciones en las que otros algoritmos fracasan. En su versión más básica, son eficientes para la resolver problemas de clasificación o predicción sencillos. Su importancia radica en su escalado en modelos de Deep Learning, que veremos en la siguiente sección.
¿Cómo lo hacen? Las redes neuronales tratan de imitar el comportamiento del cerebro humano a través de conjuntos de neuronas organizadas en capas. Cada capa se especializa en una función, procesa los datos que le llegan, y se lo pasa a la siguiente, que continúa el proceso.
Una buena analogía sería la de la realización de un trabajo de clase en equipo:
Primera capa (input layer): Un estudiante se encarga de la investigación y obtención de información.
Segunda capa (hidden layer): Otro estudiante se encarga de procesarla y redactar el trabajo.
Tercera capa (output layer): El tercer estudiante recoge la propuesta del segundo y prepara la presentación.
A base de presentar trabajos y ser puntuados por el profesor, los integrantes del equipo aprenden a hacer mejores trabajos.
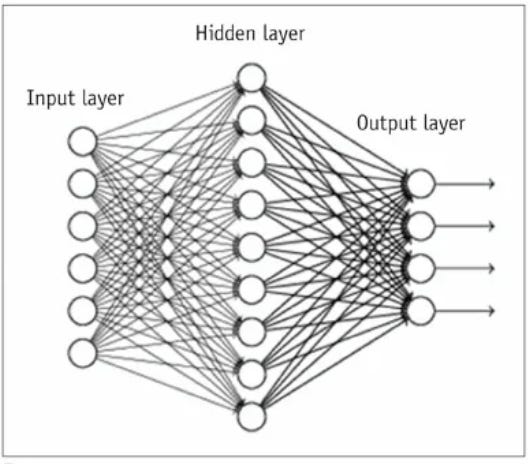
Deep Learning: Redes neuronales a escala
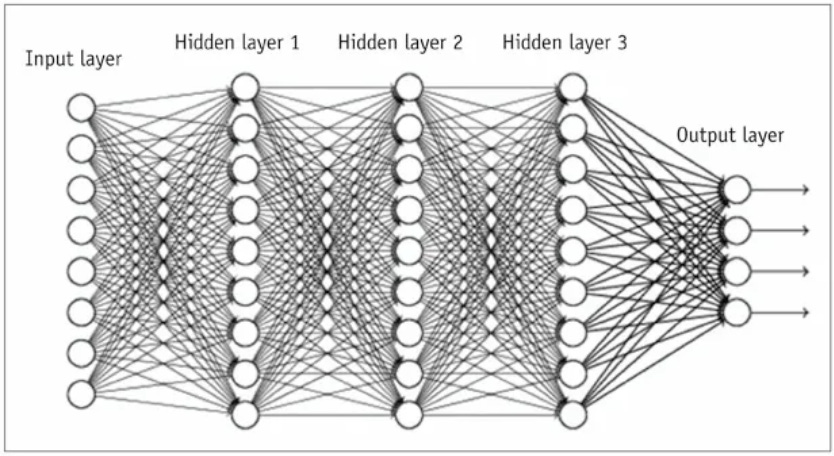
¿Qué es? Deep Learning es una subrama de Machine Learning que utiliza redes neuronales con múltiples capas (deep), para modelar problemas extremadamente complejos como reconocimiento de imágenes o de voz.
¿Por qué son importantes? Deep Learning ha permitido escalar las redes neuronales hasta niveles que en algunos casos superan incluso las capacidades humanas.
¿Cómo lo hace? El funcionamiento es igual al de una red neuronal básica, salvo que añade muchas más capas de neuronas, cada una de ellas especializada en un aspecto concreto del problema.
Pongamos por ejemplo que queremos crear un sistema que identifique fotografías de gatos a través de una red neuronal de tipo Deep Learning con cinco capas:
La primera capa examina cada foto para identificar formas: círculos o triángulos, por ejemplo.
La segunda capa busca patrones que puedan coincidir con un gato, como orejas puntiagudas (triángulos) u ojos (círculos).
La tercera capa se centra en reconocer otros patrones típicos de un gato, como los bigotes, postura o pelaje.
La cuarta capa analiza el entorno de la foto. ¿Está el gato en un entorno típico? Por ejemplo, sobre el alfeizar de una ventana o persiguiendo un ratón.
La quinta capa recoge los resultados de las pasadas por cada capa, y emite un resultado: esta foto es de un gato o no.
Este es un ejemplo extremadamente simplificado para entender cómo aprende un modelo de Deep Learning. Para que os hagáis una idea de la escala de una red neuronal de este tipo, LLaMA 3.2 90B, el modelo de LLM fundacional de Meta, está compuesto de cientos capas y millones de neuronas.
¿Qué es y cómo podemos utilizar un modelo?
Un modelo no es ni más ni menos que el resultado de entrenar nuestro algoritmo de Machine Learning.
Así, si hemos entrenado una red neuronal para reconocer fotos de gatos, el modelo será probablemente un conjunto de archivos que describirán la arquitectura de la red y los parámetros que la configuran.
Para utilizar un modelo de red neuronal en otro contexto, podríamos:
Cargar la arquitectura de la red en un entorno compatible como TensorFlow, PyTorch.
Inicializarla con sus parámetros.
De esta forma, podríamos lanzar nuevas imágenes al modelo para identificar en cuáles aparecen nuestros amigos gatunos y en cuáles no.
Casos de uso
Como os podéis imaginar, el Machine Learning, como subrama de la IA que engloba las Neural Networks y Deep Learning, tiene casi infinitas aplicaciones. Por citar algunas:
Predicciones
Predecir ventas
Predecir demanda
Evaluación de riesgos
Mantenimiento predictivo
Modelado financiero
Clasificación y categorización
Reconocimiento de imágenes
Reconocimiento de Spam
Detección de fraude
Análisis de sentimiento
Procesamiento de lenguaje natural
Clasificación
Traducción
Generación de resúmenes
Chatbots
Reconocimiento de voz
Visión
Detección de objetos
Reconocimiento facial
Conducción autónoma
Análisis imágenes resultados médicos
Sistemas de recomendación
Basados en compras recientes
Basados en contenidos
Basados en factores demográficos
Basados en intereses
Basados en comportamiento
Detección de anomalías / Seguridad
Seguridad de red
Detección de fraude
Monitorización de sistemas
Conclusión
En este artículo, hemos explorado los fundamentos de la IA, desde el Machine Learning hasta el Deep Learning, y cómo estas tecnologías forman los pilares de la Inteligencia Artificial actual.
A modo de resumen, hemos visto:
La Inteligencia Artificial es una rama de la informática que trata de crear sistemas autónomos que demuestren capacidades cognitivas humanas.
El Machine Learning es una subrama de la Inteligencia Artificial, cuyo objetivo es conseguir que los sistemas aprendan por sí mismos sin intervención humana.
Las Neural Networks es un tipo específico de algoritmo de Machine Learning que trata de imitar el comportamiento del cerebro humano.
Deep Learning es una subrama de Machine Learning, que utiliza redes neuronales con múltiples capas para resolver problemas especialmente complejos.
Un modelo es el resultado de entrenar a un algoritmo de Machine Learning. Podemos cargar el modelo en otros entornos y aprovecharnos de su aprendizaje.
La verdad, he aprendido mucho sintetizando todo este contenido, así que espero que haya sido tan útil para ti leerlo como para mí escribirlo 😃.
Dejo abierto para el futuro una posible exploración de los pilares de la Inteligencia Artificial Generativa, dónde hablaríamos de los Transformers, clave para la generación de Large Language Models, o las GAN Networks, claves para el desarrollo de sistemas de generación de imágenes como Dall-E.
Si no quieres perdértelo, te animo a que te suscribas a esta lista de correo o me sigas en Twitter o LinkedIn. ¡Gracias!
Gran resumen, a la espera de los otros prometidos. Gracias 😊